Sequential な推薦モデルやSentence BERT等の論文を理解する為に、遅ればせながら(?) Attention Is All You Needを読んだ.
n週連続 推薦システム系論文読んだシリーズ 19週目
morinota
2023/06/28
論文の基本情報
- title: Attention Is All You Need
- published date: 6 Dec 2017,
- authors: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
- url(paper): https://arxiv.org/abs/1706.03762
ざっくり論文概要
- 言わずと知れた”Transformer”を提案する論文.
- Transformerのモデルアーキテクチャと各パーツをある程度きちんと説明してくれている点がありがたかった.
- 基本的には 機械翻訳タスク を想定した内容.
この論文を読むモチベーション
- Sequential なモデルを使った推薦手法の論文を理解するのに必要になりそう.
- SentenceBERT等を用いたContent base系の推薦手法を開発・運用する上で、まずはAttention functionやTransformerが何をやってるかくらいは理解しておきたい.
まず Transformerの全体像はこうだ!
Transformerの全体像
![]()
- Transformerの入力は、source と target の2つの sequential データみたいです. 翻訳前のsentenceと 翻訳後のsentenceのイメージ🤔
- encoder-decoder 構造をしており、encoder(図左)にsourceを、decoder(図右)にtargetを入力します.
- 入力データの形状は、(batch_size \(\times\) max_sequence_length 2次元配列で各要素はtoken idx)みたいなイメージ.
- Transformerの最終的な出力は、next-token確率.
- 出力データの形状は (batch_size \(\times\) max_sequence_length \(\times\) target_vocablary_size の3次元配列で、各要素がnext-token確率)って感じだろうか🤔
Transformerの各パーツを確認していく.
- Attention function
- Scaled-dot-product Attention
- Multi-head Attention
- Position-wise Feed-Forward Networks
- Positional Encoding
- Transformer Encoder
- Transformer Decoder
Attention function について1
- \(Attention(Q, K, V)\) で表される関数.
- Query行列, Key行列, Value行列 を引数に取る.(行数がsequenceデータの長さ. 列数が各tokenの特徴量ベクトルの長さのイメージ.)
- 出力値は、value行列 を 重みづけ合計したもの.(形状はvalue行列と同じ.)
- 各valueに割り当てられた重みは、対応する key と query の compatibility function(親和性関数?)によって計算される.
- 各queryに最も親和性があるkeysを選び、対応するvaluesを取得するイメージ??🤔
- \(Attention(Q, K, V)\) は、基本的には \(Atteniton(Q, X, X)\) らしい.(i.e. Keys=Values)
- \(Q = X\) の場合、 self-attention と呼ぶ.
- \(Q \neq X\) の場合、source-to-target atteniton と呼ぶ.
Attention function について2
- ちなみに、機械翻訳タスクにおいては、以下の3通りのAttentionの使われ方が存在するらしい(Transformer内においてもこの3通りの使われ方が組み合わされている.):
- Q = X = 翻訳元の文章 とした self attention(in Encoder)
- Q = X = 翻訳対象の文章 とした self attention(in Decoder)
- Q = 翻訳対象の文章, X = 翻訳元の文章 とした source-to-target-atteniton (in Decoder)
Attention functionのお気持ち実装
Attention functionには、何種類かあるようなので、今回はInterfaceとしてお気持ち実装します.
class AttentionInterface(nn.Module):
@abc.abstractmethod
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
) -> Tensor:
"""
Parameters
----------
query : Tensor
Query行列. (seq_len * d_embed 行列)
key : Tensor
Key行列. (seq_len * d_embed 行列)
value : Tensor
Value行列. (seq_len * d_embed 行列)
Returns
Tensor
Atteniton functionの出力 (seq_len * d_embed 行列)
-------
"""
raise NotImplementedErrorScaled-dot-product Attentionについて1
以下で定義されるattention functionの一種.(Transformer内で採用されている)
\[ Attention(Q, K, V) = softmax(\frac{Q K^{T}}{\sqrt{d_k}}) V \tag{1} \]
- ここで, \(d_k\) をQuery行列 \(Q\) とKey行列 \(K\) の列数, \(d_v\) を Value行列の列数とする. (どちらも i.e. 各tokenの特徴量ベクトルの次元数のイメージ).
- 各queryと全てのkeyのdot productを計算し、それぞれを \(\sqrt{d_k}\) で割り、softmax関数を適用して各valueの重みを求めている.
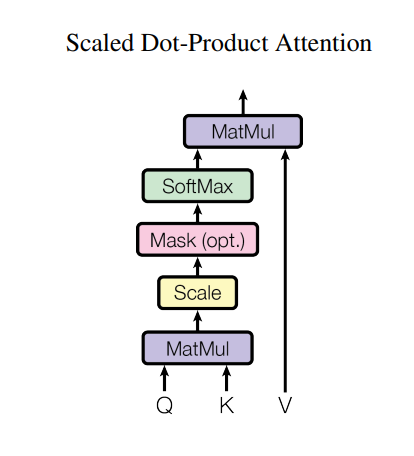
Scaled-dot-product Attentionについて2
\[ Attention(Q, K, V) = softmax(\frac{Q K^{T}}{\sqrt{d_k}}) V \tag{1} \]
- (このattention function内には、学習可能なパラメータは存在しないっぽい?. 内積と重み付け和のみで構成されてる🤔)
- 論文執筆時点で最も一般的なattention functionは、additive(加法) attention と dot-product (multiplicative=乗法) attention とのこと.
- dot-product attention の場合、\(d_k\) の大きさに依って出力値が影響を受ける為、その性質を打ち消す為に \(\sqrt{d_k}\) でscaling(正規化みたいな)している.
Scaled-dot-product Attention のお気持ち実装
AttentionInterfaceを継承したScaledDotProductAttentionをお気持ち実装してみた.
class ScaledDotProductAttention(AttentionInterface):
def __init__(self, d_k: int) -> None:
super().__init__()
self.d_k = d_k
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
mask: Optional[Tensor] = None,
) -> Tensor:
attention_weights = self._calc_attention_weights(query, key)
if mask is None:
return torch.matmul(attention_weights, value)
if mask.dim() != attention_weights.dim():
raise ValueError(
f"mask.dim != attention_weight.dim, mask.dim={mask.dim()}, attention_weight.dim={attention_weights.dim()}"
)
attention_weights_masked = attention_weights.data.masked_fill_(mask, -torch.finfo(torch.float).max)
return torch.matmul(attention_weights_masked, value)
def _calc_attention_weights(self, query: Tensor, key: Tensor) -> Tensor:
Q_K_T = torch.matmul(
query,
key.transpose(-2, -1),
)
sqrt_d_k = torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
return torch.softmax(Q_K_T / sqrt_d_k, dim=-1)Multi-head Attention について1
- \(d_{model}\) 次元の Query, Key, Value で単一のattention関数を実行するのではなく、学習した重み(線形モデル)を用いて Query, Key, Value をそれぞれ \(d_k\) 、\(d_k\) 、\(d_v\) に線形投影(=linearly project)する事を\(h\) 回行ってからattentionに入力する方法が有効だと判明しているらしい. これを実現するのがMulti-head attention.
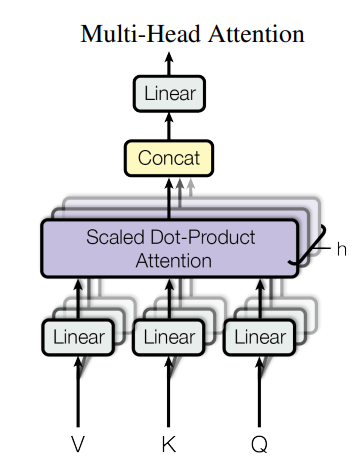
Multi-head Attention について2
\[ MultiHead(Q,K,V) = Concat(head_{1}, \cdots, head_{h}) W^{O} \\ \text{where } head_{i} = Attention(QW^{Q}_{i}, KW^{K}_{i}, VW^{V}_{i}) \tag{2} \]
- 線形投影された Query, Key, Value に対して、\(h\) 個のattention functionを並行して適用し、\(h\) 個の \(n \times d_v\) 次元の出力値を得る.
- これをconcatenate(\(n \times h d_v\) 次元になる?)して再び線形投影すると、最終的な \(n \times d_{model}\) 次元の出力値が得られる.
ここで、各線形投影に用いるパラメータ行列は以下:
\[ W^{Q}_{i} \in \mathbb{R}^{d_{model} \times d_k}, W^{K}_{i} \in \mathbb{R}^{d_{model} \times d_k}, \\ W^{V}_{i} \in \mathbb{R}^{d_{model} \times d_v}, W^{O} \in \mathbb{R}^{h * d_{v}\times d_{model}} \]
Multi-head Attention について3
- 論文のTransformerでは、 \(h = 8\) のparallel attention layers(i.e. head)を採用してる.
- \(d_{model} = 512\) として、\(d_k = d_v = \frac{d_{model}}{h} = 64\) と設定している.
- 各headsの扱う次元数が小さくなる為、総計算コストは元々のQ, K, Vにsingle head のattentionを適用する場合と同じになる. (線形投影して行列の次元数が\(n \times d_{model}\) -> \(n × d_k\) と低次元になるから…!!)
- 本論文で提案されているTransformerでは、前述した3通りのattentionの使い方で multi-head attention を使用している.
Multi-head Attention のお気持ち実装
ScaledDotProductAttentionに依存するMultiHeadAttentionをお気持ち実装してみた.
import abc
from typing import Optional
import torch
from torch import Tensor, nn
from src.attention_function import ScaledDotProductAttention
class MultiHeadAttentionInterface(nn.Module):
@abc.abstractmethod
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
mask_3d: Optional[Tensor] = None,
) -> Tensor:
raise NotImplementedError
class MultiHeadAttention(MultiHeadAttentionInterface):
def __init__(self, d_model: int, num_heads: int) -> None:
self.num_heads = num_heads
self.d_k = d_model // num_heads # query&keyもvalueも同じ埋め込み次元数の想定?
self.d_v = d_model // num_heads
self.attention_func = ScaledDotProductAttention(self.d_k)
# 以下のW^{Q}_{i}, W^{K}_{i}, W^{V}_{i}, W^{O}は学習すべきパラメータ.
self.query_linear_projectors = [nn.Linear(d_model, self.d_k) for _ in range(self.num_heads)]
self.key_linear_projectors = [nn.Linear(d_model, self.d_k) for _ in range(self.num_heads)]
self.value_linear_projectors = [nn.Linear(d_model, self.d_v) for _ in range(self.num_heads)]
self.output_linear_projector = nn.Linear(self.num_heads * self.d_v, d_model)
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
mask_3d: Optional[Tensor] = None,
) -> Tensor:
batch_size, seq_len = query.size(0), query.size(1)
if mask_3d is not None:
mask_3d = mask_3d.repeat(self.num_heads, 1, 1)
heads = []
for i in range(self.num_heads):
# linear projection for getting the inputs of each heads.
query_projected = self.query_linear_projectors[i].forward(query)
key_projected = self.key_linear_projectors[i].forward(key)
value_projected = self.value_linear_projectors[i].forward(value)
attention_output, _ = self.attention_func.forward(
query_projected,
key_projected,
value_projected,
mask_3d,
)
heads.append(attention_output)
# concat heads
concatted_output = torch.cat(heads, dim=0)
# linear projection for output
return self.output_linear_projector.forward(concatted_output)Position-wise Feed-Forward Networks について
- TransformerにおけるEncoder及びDecoder内では、multi-head attentionとセットでPosition-wise Feed-Forward Networks が採用されている.(multi-head attentionの出力がFFNの入力になる.)
- これは、2つの線形変換(=つまり中間層は一つ!)とその間のReLU活性化関数で構成される.
- 論文においては、入出力層の次元は \(d_{model} = 512\)、中間層の次元は \(d_{ff} = 2048\).
\[ FFN(x) = \max(0, xW_{1} + b_{1})W_{2} + b_{2} \tag{2} \]
Position-wise Feed-Forward Networks のお気持ち実装
PositionWiseFFNクラスを、シンプルに中間層一つのfully conected layerとして実装しました.
class PositionWiseFFNInterface(nn.Module):
"""
- Position-wise Feed-Forward Networks(FFN)は、2つの全結合層を重ねただけのシンプルな層.(中間層は一つだけ.)
- 活性化関数はRelu.
- 定式化: FFN(x) = max(0, xW_1 + b_1)W_2 + b_2
- max(0, 1つ目の層の出力)の意味が気になる...。普通付いてないっけ?
"""
@abc.abstractmethod
def forward(self, x: torch.Tensor):
raise NotImplementedError
class PositionWiseFFN(PositionWiseFFNInterface):
def __init__(self, d_model: int, d_ff: int) -> None:
"""入力層と出力層の次元数が同じなので、linear transformation?"""
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.linear_2 = nn.Linear(d_ff, d_model)
self.activate_func = nn.functional.relu
def forward(self, x: torch.Tensor) -> torch.Tensor:
middle_output = self.activate_func(self.linear_1.forward(x))
return self.linear_2.forward(middle_output)Positional Encoder について
- multi-head attention はsequential(系列)データの要素間の関係を学習できるが、再起(recurrence)も畳み込み(convolution)も含まれないのでsequentialデータの順序は考慮されない.
- そこで positional encoding を用いて、sequential データ内の position 情報 を 各tokenの特徴量ベクトルへ追加する.
- ここで”追加”というのは、sequentianlデータ内の各tokenの特徴量ベクトルに対して、positonal encodingで作った 同次元 (\(d_{model}\))のベクトルを足し算する事. (単に足し算以外のアプローチもあるのかな🤔)
- positional encodingには 学習型(i.e. 学習すべきparametersを持つ) と 固定型(i.e. 持たない) で多くの選択肢がある. (論文では以下の固定型を採用)
\[ PE_{pos, 2i} = \sin(pos/10000^{2i/d_{model}}), PE_{pos, 2i+1} = \cos(pos/10000^{2i/d_{model}}) \]
ここで、\(pos\) は sequenceデータにおける対象tokenのposition, \(2i, 2i+1\) は、positonal encoding ベクトルの各要素indexを意味する.
Positional Encoder のお気持ち実装
元のsequential特徴量ベクトル(\(n \times d_{model}\) 行列)を受け取り、positional encoding ベクトルを足し合わせた ベクトル(\(n \times d_{model}\) 行列)を返すような、PositionalEncodingクラスをお気持ち実装した.
class PositionalEncodingInterface(abc.ABC):
@abc.abstractmethod
def forward(self, x: Tensor) -> Tensor:
"""元のsequential特徴量ベクトル(n * d_{model} 行列)を受け取り、
positional encoding ベクトルを足し合わせた ベクトル(n * d_{model} 行列)を返す.
"""
raise NotImplementedError
class PositionalEncoding(PositionalEncodingInterface):
def __init__(
self,
d_model: int,
max_len: int,
device: torch.device = torch.device("cpu"),
) -> None:
"""
Parameters
----------
d_model : int
モデルの埋め込みベクトルの次元数
max_len : int
sequential データの最大長.
device : torch.device, optional
by default torch.device("cpu")
"""
super().__init__()
self.d_model = d_model
self.max_len = max_len
self.positional_encoding_weights = self._initialize_weight().to(device)
def forward(self, x: Tensor) -> Tensor:
seq_len = x.size(1)
positional_encoding_weights = self.positional_encoding_weights[:seq_len, :]
return x + positional_encoding_weights.unsqueeze(0) # 次元をあわせて足し算.
def _initialize_weight(self) -> torch.Tensor:
positional_encoding_weights = [self._calc_positional_encoding_vector(pos) for pos in range(1, self.d_model + 1)]
return torch.tensor(positional_encoding_weights).float()
def _calc_positional_encoding_vector(self, position_idx: int) -> Tensor:
"""_summary_
Parameters
----------
position_idx : int
sequentialデータにおける位置
d_model : int
特徴量ベクトルの次元数
Returns
-------
Tensor
positional encoding (d_model, )のベクトル.
"""
pe = torch.zeros(self.d_model)
odd_indices = torch.arange(0, self.d_model, 2)
even_indices = torch.arange(1, self.d_model, 2)
pe[odd_indices] = torch.cos(position_idx / (10000 ** (odd_indices.float() / self.d_model)))
pe[even_indices] = torch.sin(position_idx / (10000 ** (even_indices.float() / self.d_model)))
return peTransformer を組み立てていく
Transformer Encoder
- Transformer における Encoder は以下の層で構成される.
- Embedding層
- positional Encoding層
- Transformer Encoder Block × N個
- 各blockは multi-head attention層(self-attention) + feed forward network層 で構成される.
![]()
Transformer Encoder Blockのお気持ち実装
まずは、multi-head attention層(self-attention) + feed forward network層で構成される.TransformderEncoderBlockクラスを、MultiHeadAttentionとPositionWiseFFNをDIしてお気持ち実装する. Transformer Encoder 内で N個 直列に繋がっているやつ…!
class TransformderEncoderBlockInterface(nn.Module):
"""
multi-head attention層(self-attention) + feed forward network層で構成される.
"""
@abc.abstractmethod
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""sequential特徴量ベクトル(n * d_{model} 行列)を受け取り、
multi-head attention -> FFNに通して、
同じ形状の(n * d_{model} 行列)を返す.
"""
raise NotImplementedError
class TransformderEncoderBlock(TransformderEncoderBlockInterface):
def __init__(
self,
d_model: int,
self_attention: MultiHeadAttentionInterface,
feed_forward_network: PositionWiseFFNInterface,
dropout_rate: float,
layer_norm_epsilon: float,
) -> None:
super().__init__()
self.multi_head_attention = self_attention
self.dropout_self_attention = nn.Dropout(dropout_rate)
self.layer_norm_self_attention = nn.LayerNorm(d_model, layer_norm_epsilon)
self.ffn = feed_forward_network
self.dropout_ffn = nn.Dropout(dropout_rate)
self.layer_norm_ffn = nn.LayerNorm(d_model, layer_norm_epsilon)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.layer_norm_self_attention(self._self_attention_block)
return self.layer_norm_ffn(self._feed_forward_block(x))
def _self_attention_block(self, x: torch.Tensor) -> torch.Tensor:
x = self.multi_head_attention.forward(x, x, x) # self-attention
return self.dropout_self_attention.forward(x)
def _feed_forward_block(self, x: torch.Tensor) -> torch.Tensor:
x = self.ffn.forward(x)
return self.dropout_ffn.forward(x)Transformer Encoderのお気持ち実装
続いて、Embedding層 + Positional Encoding層 + Transformer Encoder Block × N個 で形成されるTransformerEncoderクラスをお気持ち実装する.
class TransformerEncoderInterface(nn.Module):
"""
- Transformer における Encoder は以下の層で構成される.
- Embedding層
- positional Encoding層
- (multi-head attention層 + feed forward network層) = TransformerEncoderBlock層をn層重ねた層.
"""
@abc.abstractmethod
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
- まずEmbedding
- 次にPositional Encoding
- TransformerEncoderBlock層 × n
"""
raise NotImplementedError
class TransformerEncoder(TransformerEncoderInterface):
def __init__(
self,
d_model: int,
N: int,
positional_encoding: PositionalEncodingInterface,
self_attention: MultiHeadAttentionInterface,
feed_forward_network: PositionWiseFFNInterface,
vocab_size: int,
max_len: int,
padding_idx: int,
dropout_rate: float,
layer_norm_epsilon: float,
device: torch.device = torch.device("cpu"),
) -> None:
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model, padding_idx)
self.positional_encoding = positional_encoding
self.encoder_blocks = nn.ModuleList(
[
TransformderEncoderBlock(
d_model, self_attention, feed_forward_network, dropout_rate, layer_norm_epsilon
)
for _ in range(N)
]
)
# ↓流れがわかりやす~い!
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.embedding(x)
x = self.positional_encoding.forward(x)
for encoder_block in self.encoder_blocks:
x = encoder_block.forward(x)
return xTransformer Decoder
- Transformer Decoderは以下の層で構成される:
- Embedding層:
- Positional Encoding層:
- Transformer Decoder Block × N個
- 各blockは masked multi-head attention層(self-attention) + multi-head attention層(source-to-target-attention) + feed forward network層 で構成される.
![]()
Transformer Decoder Blockのお気持ち実装
まずは、masked multi-head attention層(self-attention) + multi-head attention層(source-to-target-attention) + feed forward network層 で構成される.TransformderDecoderBlockクラスを、MultiHeadAttentionとPositionWiseFFNをDIしてお気持ち実装する. Transformer Decoder 内で N個 直列に繋がっているやつ…!
class TransformerDecoderBlockInterface(nn.Module):
"""
masked multi-head attention層(self-attention) + multi-head attention層(source-to-target-attention) + feed forward network層 で構成される
"""
@abc.abstractmethod
def forward(
self,
tgt: Tensor, # Decoder input
src: Tensor, # Encoder output
mask_src_to_tgt: Tensor,
mask_self: Tensor,
) -> Tensor:
raise NotImplementedError
class TransformerDecoderBlock(TransformerDecoderBlockInterface):
def __init__(
self,
d_model: int,
self_attention: MultiHeadAttentionInterface,
src_to_tgt_attention: MultiHeadAttentionInterface,
feed_forward_network: PositionWiseFFNInterface,
dropout_rate: float,
layer_norm_epsilon: float,
) -> None:
super().__init__()
# self-attention
self.self_attention = self_attention
self.dropout_self_attention = nn.Dropout(dropout_rate)
self.layer_norm_self_attention = nn.LayerNorm(d_model, layer_norm_epsilon)
# source-to-target attention
self.src_to_tgt_attention = src_to_tgt_attention
self.dropout_src_to_tgt_attention = nn.Dropout(dropout_rate)
self.layer_norm_src_to_tgt_attention = nn.LayerNorm(d_model, layer_norm_epsilon)
# feed forward network
self.ffn = feed_forward_network
self.dropout_ffn = nn.Dropout(dropout_rate)
self.layer_norm_ffn = nn.LayerNorm(d_model, layer_norm_epsilon)
def forward(
self,
tgt: Tensor,
src: Tensor,
mask_src_to_tgt: Tensor,
mask_self: Tensor,
) -> Tensor:
# input to self-attention function
tgt_self_attentioned = self.dropout_self_attention(
self.self_attention.forward(tgt, tgt, tgt, mask_self),
)
tgt_self_attentioned_norm = self.layer_norm_self_attention(
tgt + tgt_self_attentioned,
)
# input to src-to-tgt-attention function
x_src_to_tgt_attentioned = self.dropout_src_to_tgt_attention(
self.src_to_tgt_attention.forward(tgt_self_attentioned_norm, src, src, mask_src_to_tgt)
)
x_src_to_tgt_attentioned_norm = self.layer_norm_src_to_tgt_attention(
tgt_self_attentioned + x_src_to_tgt_attentioned
)
# input to feed forward network
x_ffn = self.dropout_ffn(self.ffn.forward(x_src_to_tgt_attentioned_norm))
return self.layer_norm_ffn(x_src_to_tgt_attentioned_norm + x_ffn)Transformer Decoderのお気持ち実装
続いて、Embedding層 + Positional Encoding層 + Transformer Decoder Block × N個 で形成されるTransformerDecoderクラスをお気持ち実装する.
class TranformerDecoderInterface(nn.Module):
"""
- Transformer Decoderは以下の層で構成される:
- Embedding Layer:
- Positional Encoding Layer:
- Transformer Decoder Block × N:
- 各blockは(Masked multi-head attention + Multi-head attention + Feed Forward Network)で構成.
"""
@abc.abstractmethod
def calc(
self,
tgt: Tensor,
src: Tensor,
mask_src_tgt: Tensor,
mask_self: Tensor,
) -> Tensor:
raise NotImplementedError
class TransformerDecoder(TranformerDecoderInterface):
def __init__(
self,
d_model: int,
N: int,
positional_encoding: PositionalEncodingInterface,
self_attention: MultiHeadAttentionInterface,
src_to_tgt_attention: MultiHeadAttentionInterface,
feed_forward_network: PositionWiseFFNInterface,
vocab_size: int,
max_len: int,
padding_idx: int,
dropout_rate: float,
layer_norm_epsilon: float,
device: torch.device = torch.device("cpu"),
) -> None:
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model, padding_idx)
self.positional_encoding = positional_encoding
self.decoder_blocks = nn.ModuleList(
[
TransformerDecoderBlock(
d_model,
self_attention,
src_to_tgt_attention,
feed_forward_network,
dropout_rate,
layer_norm_epsilon,
)
for _ in range(N)
]
)
# ↓流れがわかりやす~い!
def forward(
self,
tgt: Tensor,
src: Tensor,
mask_src_tgt: Tensor,
mask_self: Tensor,
) -> Tensor:
tgt = self.embedding(tgt)
tgt = self.positional_encoding.forward(tgt)
for decoder_block in self.decoder_blocks:
tgt = decoder_block.forward(
tgt,
src,
mask_src_tgt,
mask_self,
)
return tgtTransformer の全体像はこんな感じでした.
すでにEncoder部分とDecoder部分は実装済みなので、あとはDecoderの出力値に対する 線形変換の層(\(d_{model}\) -> target_vocablary_numに次元数を増やすような変換. この場合は線形変換と言って良いのか…?)と、各要素の値をnext-token確率に変換する softmax関数の層を追加すればOKのはず…!
![]()
Transformer のお気持ち実装
class TransformerInterface(nn.Module):
@abc.abstractmethod
def forward(self, src: Tensor, tgt: Tensor) -> Tensor:
"""
Parameters
----------
src : Tensor
翻訳元のsequential データ(各要素はtokenのid)
tgt : Tensor
翻訳先のsequential データ(各要素はtokenのid)
Return
Tensor
"""
raise NotImplementedError
class Transformer(TransformerInterface):
def __init__(
self,
src_vocab_size: int,
tgt_vocab_size: int,
mask_for_src_to_tgt: Tensor,
mask_for_self_attn: Tensor,
max_len: int,
d_model: int = 512,
heads_num: int = 8,
d_ff: int = 2048,
N: int = 6,
dropout_rate: float = 0.1,
layer_norm_epsilon: float = 1e-5,
pad_idx: int = 0,
device: torch.device = torch.device("cpu"),
) -> None:
super().__init__()
self.src_vocab_size = src_vocab_size
self.tgt_vocab_size = tgt_vocab_size
self.d_model = d_model
self.max_len = max_len
self.heads_num = heads_num
self.d_ff = d_ff
self.N = N
self.dropout_rate = dropout_rate
self.layer_norm_epsilon = layer_norm_epsilon
self.pad_idx = pad_idx
self.device = device
self.mask_for_src_to_tgt = mask_for_src_to_tgt
self.mask_self_attn = mask_for_self_attn
self.encoder = TransformerEncoder(
self.d_model,
self.N,
PositionalEncoding(self.d_model, self.max_len, self.device),
MultiHeadAttention(self.d_model, self.heads_num),
PositionWiseFFN(self.d_model, self.d_ff),
self.src_vocab_size,
self.max_len,
self.pad_idx,
self.dropout_rate,
self.layer_norm_epsilon,
self.device,
)
self.decoder = TransformerDecoder(
self.d_model,
self.N,
PositionalEncoding(self.d_model, self.max_len, self.device),
MultiHeadAttention(self.d_model, self.heads_num),
MultiHeadAttention(self.d_model, self.heads_num),
PositionWiseFFN(self.d_model, self.d_ff),
self.src_vocab_size,
self.max_len,
self.pad_idx,
self.dropout_rate,
self.layer_norm_epsilon,
self.device,
)
self.linear_trans = nn.Linear(d_model, tgt_vocab_size)
self.softmax_func = nn.Softmax(dim=1)
def forward(self, src: Tensor, tgt: Tensor) -> Tensor:
encode_output = self.encoder.forward(src)
decode_output = self.decoder.forward(
tgt,
encode_output,
self.mask_for_src_to_tgt,
self.mask_self_attn,
)
linear_output = self.linear_trans.forward(decode_output)
return self.softmax_func.forward(linear_output)感想
- Attention, Self-Attention, Transformer等、NLPを始めとした機械学習界隈で良く聞く関数(モデル?)がどんな構造で、どんな入力を受け取って、どんなパラメータを持っていて、どんな出力をするのか、ざっくり把握できた気がする. (なぜこの構造が性能が良いのか、等はよくわかってない.)
- これで、Sequentialなモデルを使った推薦手法へのアレルギーが減ると良いなと思う. あと、論文読み会でこれらの用語が出てきた時に「うんうん、あれね」となんとなく想像できるようになるはず…
- ただ、“All You Need”具合は良くわかってない…!
次に読むべき論文
- 2022 RecSysのベストペーパーの一つ. Denoising Self-Attentive Sequential Recommendation
- BERTの元論文. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- SentenceBERTの論文. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
論文の理解やお気持ち実装の際に以下のtechブログを参考にさせていただきました! ありがたい…👋 (↓のブログの実装と異なり、自分のお気持ち実装はおそらく動作しません…!)
